Easing gently into OpenSRF
- Abstract
- Introducing OpenSRF
- Enough jibber-jabber: writing an OpenSRF service
- Registering a service with the OpenSRF configuration files
- Calling an OpenSRF method
- Accepting and returning more interesting data types
- Accepting and returning Evergreen objects
- Returning streaming results
- Error! Warning! Info! Debug!
- Caching results: one secret of scalability
- Initializing the service and its children: child labour
- Retrieving configuration settings
- Getting under the covers with OpenSRF
- Evergreen-specific OpenSRF services
- Evergreen after one year: reflections on OpenSRF
- Summary
- Appendix: Python client
Abstract
The Evergreen open-source library system serves library consortia composed of hundreds of branches with millions of patrons - for example, the Georgia Public Library Service PINES system. One of the claimed advantages of Evergreen over alternative integrated library systems is the underlying Open Service Request Framework (OpenSRF, pronounced "open surf") architecture. This article introduces OpenSRF, demonstrates how to build OpenSRF services through simple code examples, and explains the technical foundations on which OpenSRF is built.
Introducing OpenSRF
OpenSRF is a message routing network that offers scalability and failover support for individual services and entire servers with minimal development and deployment overhead. You can use OpenSRF to build loosely-coupled applications that can be deployed on a single server or on clusters of geographically distributed servers using the same code and minimal configuration changes. Although copyright statements on some of the OpenSRF code date back to Mike Rylander’s original explorations in 2000, Evergreen was the first major application to be developed with, and to take full advantage of, the OpenSRF architecture starting in 2004. The first official release of OpenSRF was 0.1 in February 2005 (http://evergreen-ils.org/blog/?p=21), but OpenSRF’s development continues a steady pace of enhancement and refinement, with the release of 1.0.0 in October 2008 and the most recent release of 1.2.2 in February 2010.
OpenSRF is a distinct break from the architectural approach used by previous library systems and has more in common with modern Web applications. The traditional "scale-up" approach to serve more transactions is to purchase a server with more CPUs and more RAM, possibly splitting the load between a Web server, a database server, and a business logic server. Evergreen, however, is built on the Open Service Request Framework (OpenSRF) architecture, which firmly embraces the "scale-out" approach of spreading transaction load over cheap commodity servers. The initial GPLS PINES hardware cluster, while certainly impressive, may have offered the misleading impression that Evergreen is complex and requires a lot of hardware to run.
This article hopes to correct any such lingering impression by demonstrating that OpenSRF itself is an extremely simple architecture on which one can easily build applications of many kinds – not just library applications – and that you can use a number of different languages to call and implement OpenSRF methods with a minimal learning curve. With an application built on OpenSRF, when you identify a bottleneck in your application’s business logic layer, you can adjust the number of the processes serving that particular bottleneck on each of your servers; or if the problem is that your service is resource-hungry, you could add an inexpensive server to your cluster and dedicate it to running that resource-hungry service.
Programming language support
If you need to develop an entirely new OpenSRF service, you can choose from a number of different languages in which to implement that service. OpenSRF client language bindings have been written for C, Java, JavaScript, Perl, and Python, and server language bindings have been written for C, Perl, and Python. This article uses Perl examples as a lowest common denominator programming language. Writing an OpenSRF binding for another language is a relatively small task if that language offers libraries that support the core technologies on which OpenSRF depends:
-
Extensible Messaging and Presence Protocol (XMPP, sometimes referred to as Jabber) - provides the base messaging infrastructure between OpenSRF clients and servers
-
JavaScript Object Notation (JSON) - serializes the content of each XMPP message in a standardized and concise format
-
memcached - provides the caching service
-
syslog - the standard UNIX logging service
Unfortunately, the OpenSRF reference documentation, although augmented by the OpenSRF glossary, blog posts like the description of OpenSRF and Jabber, and even this article, is not a sufficient substitute for a complete specification on which one could implement a language binding. The recommended option for would-be developers of another language binding is to use the Python implementation as the cleanest basis for a port to another language.
OpenSRF communication flows over XMPP
The XMPP messaging service underpins OpenSRF, requiring an XMPP server such
as ejabberd. When you start OpenSRF, the first XMPP
clients that connect to the XMPP server are the OpenSRF public and private
routers. OpenSRF routers maintain a list of available services and connect
clients to available services. When an OpenSRF service starts, it establishes a
connection to the XMPP server and registers itself with the private router. The
OpenSRF configuration contains a list of public OpenSRF services, each of which
must also register with the public router. Services and clients connect to the
XMPP server using a single set of XMPP client credentials (for example,
opensrf@private.localhost), but use XMPP resource identifiers to
differentiate themselves in the Jabber ID (JID) for each connection. For
example, the JID for a copy of the opensrf.simple-text service with process
ID 6285 that has connected to the private.localhost domain using the
opensrf XMPP client credentials could be
opensrf@private.localhost/opensrf.simple-text_drone_at_localhost_6285.
OpenSRF communication flows over HTTP
Any OpenSRF service registered with the public router is accessible via the OpenSRF HTTP Translator. The OpenSRF HTTP Translator implements the OpenSRF-over-HTTP proposed specification as an Apache module that translates HTTP requests into OpenSRF requests and returns OpenSRF results as HTTP results to the initiating HTTP client.
# curl request broken up over multiple lines for legibility
curl -H "X-OpenSRF-service: opensrf.simple-text" \ (1)
--data 'osrf-msg=[ \ (2)
{"__c":"osrfMessage","__p":{"threadTrace":0,"locale":"en-CA", \ (3)
"type":"REQUEST","payload": {"__c":"osrfMethod","__p": \
{"method":"opensrf.simple-text.reverse","params":["foobar"]} \
}} \
}]' \
http://localhost/osrf-http-translator \ (4)| 1 | The X-OpenSRF-service header identifies the OpenSRF service of interest. |
| 2 | The POST request consists of a single parameter, the osrf-msg value,
which contains a JSON array. |
| 3 | The first object is an OpenSRF message ("c":"osrfMessage") with a set of
parameters ("p":{}) containing:
|
| 4 | The URL on which the OpenSRF HTTP translator is listening,
/osrf-http-translator is the default location in the Apache example
configuration files shipped with the OpenSRF source, but this is configurable. |
# HTTP response broken up over multiple lines for legibility
[{"__c":"osrfMessage","__p": \ (1)
{"threadTrace":0, "payload": \ (2)
{"__c":"osrfResult","__p": \ (3)
{"status":"OK","content":"raboof","statusCode":200} \ (4)
},"type":"RESULT","locale":"en-CA" \ (5)
}
},
{"__c":"osrfMessage","__p": \ (6)
{"threadTrace":0,"payload": \ (7)
{"__c":"osrfConnectStatus","__p": \ (8)
{"status":"Request Complete","statusCode":205} \ (9)
},"type":"STATUS","locale":"en-CA" \ (10)
}
}]| 1 | The OpenSRF HTTP Translator returns an array of JSON objects in its
response. Each object in the response is an OpenSRF message
("c":"osrfMessage") with a collection of response parameters ("p":). |
| 2 | The OpenSRF message identifier ("threadTrace":0) confirms that this
message is in response to the request matching the same identifier. |
| 3 | The message includes a payload JSON object ("payload":) with an OpenSRF
result for the request ("__c":"osrfResult"). |
| 4 | The result includes a status indicator string ("status":"OK"), the content
of the result response - in this case, a single string "raboof"
("content":"raboof") - and an integer status code for the request
("statusCode":200). |
| 5 | The message also includes the message type ("type":"RESULT") and the
message locale ("locale":"en-CA"). |
| 6 | The second message in the set of results from the response. |
| 7 | Again, the message identifier confirms that this message is in response to a particular request. |
| 8 | The payload of the message denotes that this message is an
OpenSRF connection status message ("__c":"osrfConnectStatus"), with some
information about the particular OpenSRF connection that was used for this
request. |
| 9 | The response parameters for an OpenSRF connection status message include a
verbose status ("status":"Request Complete") and an integer status code for
the connection status (`"statusCode":205). |
| 10 | The message also includes the message type ("type":"RESULT") and the
message locale ("locale":"en-CA"). |
Before adding a new public OpenSRF service, ensure that it does
not introduce privilege escalation or unchecked access to data. For example,
the Evergreen open-ils.cstore private service is an object-relational mapper
that provides read and write access to the entire Evergreen database, so it
would be catastrophic to expose that service publicly. In comparison, the
Evergreen open-ils.pcrud public service offers the same functionality as
open-ils.cstore to any connected HTTP client or OpenSRF client, but the
additional authentication and authorization layer in open-ils.pcrud prevents
unchecked access to Evergreen’s data.
|
Stateless and stateful connections
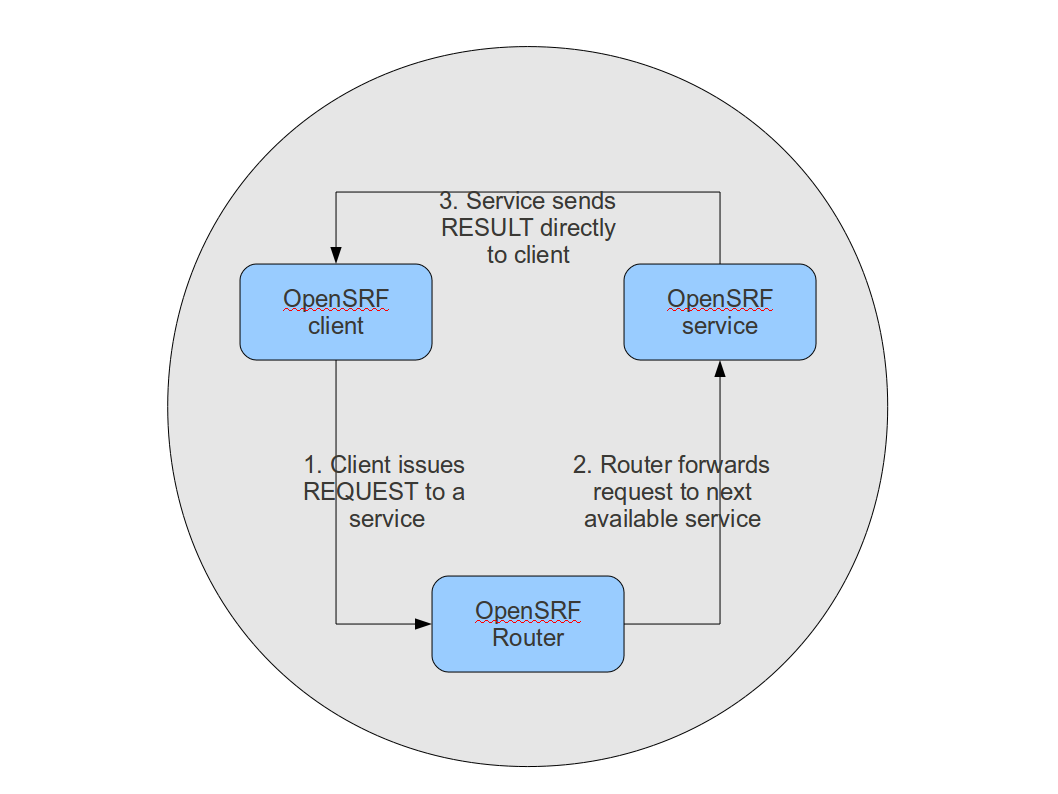
OpenSRF supports both stateless and stateful connections. When an OpenSRF
client issues a REQUEST message in a stateless connection, the router
forwards the request to the next available service and the service returns the
result directly to the client.
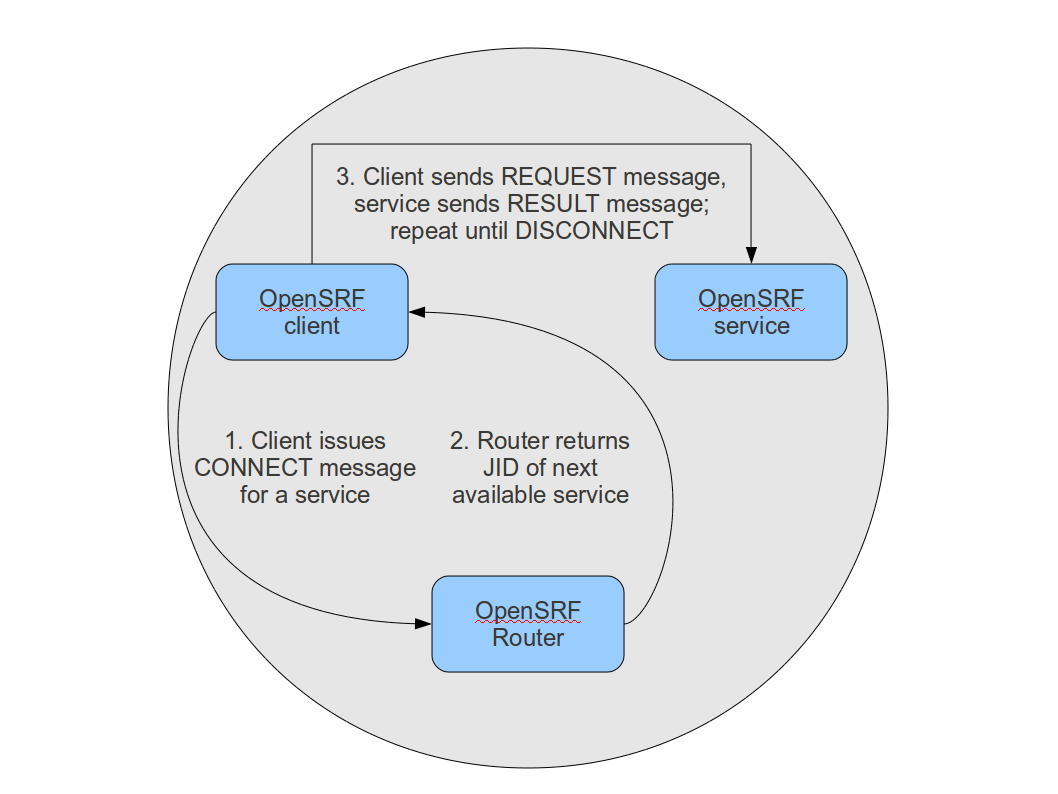
When an OpenSRF client issues a CONNECT message to create a stateful connection, the
router returns the Jabber ID of the next available service to the client so
that the client can issue one or more REQUEST message directly to that
particular service and the service will return corresponding RESULT messages
directly to the client. Until the client issues a DISCONNECT message, that
particular service is only available to the requesting client. Stateful connections
are useful for clients that need to make many requests from a particular service,
as it avoids the intermediary step of contacting the router for each request, as
well as for operations that require a controlled sequence of commands, such as a
set of database INSERT, UPDATE, and DELETE statements within a transaction.
Enough jibber-jabber: writing an OpenSRF service
Imagine an application architecture in which 10 lines of Perl or Python, using
the data types native to each language, are enough to implement a method that
can then be deployed and invoked seamlessly across hundreds of servers. You
have just imagined developing with OpenSRF – it is truly that simple. Under the
covers, of course, the OpenSRF language bindings do an incredible amount of
work on behalf of the developer. An OpenSRF application consists of one or more
OpenSRF services that expose methods: for example, the opensrf.simple-text
demonstration
service exposes the opensrf.simple-text.split() and
opensrf.simple-text.reverse() methods. Each method accepts zero or more
arguments and returns zero or one results. The data types supported by OpenSRF
arguments and results are typical core language data types: strings, numbers,
booleans, arrays, and hashes.
To implement a new OpenSRF service, perform the following steps:
-
Include the base OpenSRF support libraries
-
Write the code for each of your OpenSRF methods as separate procedures
-
Register each method
-
Add the service definition to the OpenSRF configuration files
For example, the following code implements an OpenSRF service. The service
includes one method named opensrf.simple-text.reverse() that accepts one
string as input and returns the reversed version of that string:
#!/usr/bin/perl
package OpenSRF::Application::Demo::SimpleText;
use strict;
use OpenSRF::Application;
use parent qw/OpenSRF::Application/;
sub text_reverse {
my ($self , $conn, $text) = @_;
my $reversed_text = scalar reverse($text);
return $reversed_text;
}
__PACKAGE__->register_method(
method => 'text_reverse',
api_name => 'opensrf.simple-text.reverse'
);Ten lines of code, and we have a complete OpenSRF service that exposes a single
method and could be deployed quickly on a cluster of servers to meet your
application’s ravenous demand for reversed strings! If you’re unfamiliar with
Perl, the use OpenSRF::Application; use parent qw/OpenSRF::Application/;
lines tell this package to inherit methods and properties from the
OpenSRF::Application module. For example, the call to
PACKAGE→register_method() is defined in OpenSRF::Application but due to
inheritance is available in this package (named by the special Perl symbol
PACKAGE that contains the current package name). The register_method()
procedure is how we introduce a method to the rest of the OpenSRF world.
Registering a service with the OpenSRF configuration files
Two files control most of the configuration for OpenSRF:
-
opensrf.xmlcontains the configuration for the service itself as well as a list of which application servers in your OpenSRF cluster should start the service -
opensrf_core.xml(often referred to as the "bootstrap configuration" file) contains the OpenSRF networking information, including the XMPP server connection credentials for the public and private routers; you only need to touch this for a new service if the new service needs to be accessible via the public router
Begin by defining the service itself in opensrf.xml. To register the
opensrf.simple-text service, add the following section to the <apps>
element (corresponding to the XPath /opensrf/default/apps/):
<apps>
<opensrf.simple-text> (1)
<keepalive>3</keepalive> (2)
<stateless>1</stateless> (3)
<language>perl</language> (4)
<implementation>OpenSRF::Application::Demo::SimpleText</implementation> (5)
<max_requests>100</max_requests> (6)
<unix_config>
<max_requests>1000</max_requests> (7)
<unix_log>opensrf.simple-text_unix.log</unix_log> (8)
<unix_sock>opensrf.simple-text_unix.sock</unix_sock> (9)
<unix_pid>opensrf.simple-text_unix.pid</unix_pid> (10)
<min_children>5</min_children> (11)
<max_children>15</max_children> (12)
<min_spare_children>2</min_spare_children> (13)
<max_spare_children>5</max_spare_children> (14)
</unix_config>
</opensrf.simple-text>
<!-- other OpenSRF services registered here... -->
</apps>| 1 | The element name is the name that the OpenSRF control scripts use to refer to the service. |
| 2 | Specifies the interval (in seconds) between checks to determine if the service is still running. |
| 3 | Specifies whether OpenSRF clients can call methods from this service
without first having to create a connection to a specific service backend
process for that service. If the value is 1, then the client can simply
issue a request and the router will forward the request to an available
service and the result will be returned directly to the client. |
| 4 | Specifies the programming language in which the service is implemented |
| 5 | Specifies the name of the library or module in which the service is implemented |
| 6 | (C implementations): Specifies the maximum number of requests a process serves before it is killed and replaced by a new process. |
| 7 | (Perl implementations): Specifies the maximum number of requests a process serves before it is killed and replaced by a new process. |
| 8 | The name of the log file for language-specific log messages such as syntax warnings. |
| 9 | The name of the UNIX socket used for inter-process communications. |
| 10 | The name of the PID file for the master process for the service. |
| 11 | The minimum number of child processes that should be running at any given time. |
| 12 | The maximum number of child processes that should be running at any given time. |
| 13 | The minimum number of child processes that should be available to handle incoming requests. If there are fewer than this number of spare child processes, new processes will be spawned. |
| 14 | The maximum number of child processes that should be available to handle incoming requests. If there are more than this number of spare child processes, the extra processes will be killed. |
To make the service accessible via the public router, you must also
edit the opensrf_core.xml configuration file to add the service to the list
of publicly accessible services:
opensrf_core.xml<router> (1)
<!-- This is the public router. On this router, we only register applications
which should be accessible to everyone on the opensrf network -->
<name>router</name>
<domain>public.localhost</domain> (2)
<services>
<service>opensrf.math</service>
<service>opensrf.simple-text</service> (3)
</services>
</router>| 1 | This section of the opensrf_core.xml file is located at XPath
/config/opensrf/routers/. |
| 2 | public.localhost is the canonical public router domain in the OpenSRF
installation instructions. |
| 3 | Each <service> element contained in the <services> element
offers their services via the public router as well as the private router. |
Once you have defined the new service, you must restart the OpenSRF Router to retrieve the new configuration and start or restart the service itself.
Calling an OpenSRF method
OpenSRF clients in any supported language can invoke OpenSRF services in any
supported language. So let’s see a few examples of how we can call our fancy
new opensrf.simple-text.reverse() method:
Calling OpenSRF methods from the srfsh client
srfsh is a command-line tool installed with OpenSRF that you can use to call
OpenSRF methods. To call an OpenSRF method, issue the request command and pass
the OpenSRF service and method name as the first two arguments; then pass a list
of JSON objects as the arguments to the method being invoked.
The following example calls the opensrf.simple-text.reverse method of the
opensrf.simple-text OpenSRF service, passing the string "foobar" as the
only method argument:
$ srfsh
srfsh # request opensrf.simple-text opensrf.simple-text.reverse "foobar"
Received Data: "raboof"
=------------------------------------
Request Completed Successfully
Request Time in seconds: 0.016718
=------------------------------------Getting documentation for OpenSRF methods from the srfsh client
The srfsh client also gives you command-line access to retrieving metadata
about OpenSRF services and methods. For a given OpenSRF method, for example,
you can retrieve information such as the minimum number of required arguments,
the data type and a description of each argument, the package or library in
which the method is implemented, and a description of the method. To retrieve
the documentation for an opensrf method from srfsh, issue the introspect
command, followed by the name of the OpenSRF service and (optionally) the
name of the OpenSRF method. If you do not pass a method name to the introspect
command, srfsh lists all of the methods offered by the service. If you pass
a partial method name, srfsh lists all of the methods that match that portion
of the method name.
| The quality and availability of the descriptive information for each method depends on the developer to register the method with complete and accurate information. The quality varies across the set of OpenSRF and Evergreen APIs, although some effort is being put towards improving the state of the internal documentation. |
srfsh# introspect opensrf.simple-text "opensrf.simple-text.reverse"
--> opensrf.simple-text
Received Data: {
"__c":"opensrf.simple-text",
"__p":{
"api_level":1,
"stream":0, \ (1)
"object_hint":"OpenSRF_Application_Demo_SimpleText",
"remote":0,
"package":"OpenSRF::Application::Demo::SimpleText", \ (2)
"api_name":"opensrf.simple-text.reverse", \ (3)
"server_class":"opensrf.simple-text",
"signature":{ \ (4)
"params":[ \ (5)
{
"desc":"The string to reverse",
"name":"text",
"type":"string"
}
],
"desc":"Returns the input string in reverse order\n", \ (6)
"return":{ \ (7)
"desc":"Returns the input string in reverse order",
"type":"string"
}
},
"method":"text_reverse", \ (8)
"argc":1 \ (9)
}
}| 1 | stream denotes whether the method supports streaming responses or not. |
| 2 | package identifies which package or library implements the method. |
| 3 | api_name identifies the name of the OpenSRF method. |
| 4 | signature is a hash that describes the parameters for the method. |
| 5 | params is an array of hashes describing each parameter in the method;
each parameter has a description (desc), name (name), and type (type). |
| 6 | desc is a string that describes the method itself. |
| 7 | return is a hash that describes the return value for the method; it
contains a description of the return value (desc) and the type of the
returned value (type). |
| 8 | method identifies the name of the function or method in the source
implementation. |
| 9 | argc is an integer describing the minimum number of arguments that
must be passed to this method. |
Calling OpenSRF methods from Perl applications
To call an OpenSRF method from Perl, you must connect to the OpenSRF service, issue the request to the method, and then retrieve the results.
#/usr/bin/perl
use strict;
use OpenSRF::AppSession;
use OpenSRF::System;
OpenSRF::System->bootstrap_client(config_file => '/openils/conf/opensrf_core.xml'); (1)
my $session = OpenSRF::AppSession->create("opensrf.simple-text"); (2)
print "substring: Accepts a string and a number as input, returns a string\n";
my $result = $session->request("opensrf.simple-text.substring", "foobar", 3); (3)
my $request = $result->gather(); (4)
print "Substring: $request\n\n";
print "split: Accepts two strings as input, returns an array of strings\n";
$request = $session->request("opensrf.simple-text.split", "This is a test", " "); (5)
my $output = "Split: [";
my $element;
while ($element = $request->recv()) { (6)
$output .= $element->content . ", "; (7)
}
$output =~ s/, $/]/;
print $output . "\n\n";
print "statistics: Accepts an array of strings as input, returns a hash\n";
my @many_strings = [
"First I think I'll have breakfast",
"Then I think that lunch would be nice",
"And then seventy desserts to finish off the day"
];
$result = $session->request("opensrf.simple-text.statistics", @many_strings); (8)
$request = $result->gather(); (9)
print "Length: " . $result->{'length'} . "\n";
print "Word count: " . $result->{'word_count'} . "\n";
$session->disconnect(); (10)| 1 | The OpenSRF::System→bootstrap_client() method reads the OpenSRF
configuration information from the indicated file and creates an XMPP client
connection based on that information. |
| 2 | The OpenSRF::AppSession→create() method accepts one argument - the name
of the OpenSRF service to which you want to want to make one or more requests -
and returns an object prepared to use the client connection to make those
requests. |
| 3 | The OpenSRF::AppSession→request() method accepts a minimum of one
argument - the name of the OpenSRF method to which you want to make a request -
followed by zero or more arguments to pass to the OpenSRF method as input
values. This example passes a string and an integer to the
opensrf.simple-text.substring method defined by the opensrf.simple-text
OpenSRF service. |
| 4 | The gather() method, called on the result object returned by the
request() method, iterates over all of the possible results from the result
object and returns a single variable. |
| 5 | This request() call passes two strings to the opensrf.simple-text.split
method defined by the opensrf.simple-text OpenSRF service and returns (via
gather()) a reference to an array of results. |
| 6 | The opensrf.simple-text.split() method is a streaming method that
returns an array of results with one element per recv() call on the
result object. We could use the gather() method to retrieve all of the
results in a single array reference, but instead we simply iterate over
the result variable until there are no more results to retrieve. |
| 7 | While the gather() convenience method returns only the content of the
complete set of results for a given request, the recv() method returns an
OpenSRF result object with status, statusCode, and content fields as
we saw in the HTTP results example. |
| 8 | This request() call passes an array to the
opensrf.simple-text.statistics method defined by the opensrf.simple-text
OpenSRF service. |
| 9 | The result object returns a hash reference via gather(). The hash
contains the length and word_count keys we defined in the method. |
| 10 | The OpenSRF::AppSession→disconnect() method closes the XMPP client
connection and cleans up resources associated with the session. |
Accepting and returning more interesting data types
Of course, the example of accepting a single string and returning a single string is not very interesting. In real life, our applications tend to pass around multiple arguments, including arrays and hashes. Fortunately, OpenSRF makes that easy to deal with; in Perl, for example, returning a reference to the data type does the right thing. In the following example of a method that returns a list, we accept two arguments of type string: the string to be split, and the delimiter that should be used to split the string.
sub text_split {
my $self = shift;
my $conn = shift;
my $text = shift;
my $delimiter = shift || ' ';
my @split_text = split $delimiter, $text;
return \@split_text;
}
__PACKAGE__->register_method(
method => 'text_split',
api_name => 'opensrf.simple-text.split'
);We simply return a reference to the list, and OpenSRF does the rest of the work for us to convert the data into the language-independent format that is then returned to the caller. As a caller of a given method, you must rely on the documentation used to register to determine the data structures - if the developer has added the appropriate documentation.
Accepting and returning Evergreen objects
OpenSRF is agnostic about objects; its role is to pass JSON back and forth between OpenSRF clients and services, and it allows the specific clients and services to define their own semantics for the JSON structures. On top of that infrastructure, Evergreen offers the fieldmapper: an object-relational mapper that provides a complete definition of all objects, their properties, their relationships to other objects, the permissions required to create, read, update, or delete objects of that type, and the database table or view on which they are based.
The Evergreen fieldmapper offers a great deal of convenience for working with complex system objects beyond the basic mapping of classes to database schemas. Although the result is passed over the wire as a JSON object containing the indicated fields, fieldmapper-aware clients then turn those JSON objects into native objects with setter / getter methods for each field.
All of this metadata about Evergreen objects is defined in the
fieldmapper configuration file (/openils/conf/fm_IDL.xml), and access to
these classes is provided by the open-ils.cstore, open-ils.pcrud, and
open-ils.reporter-store OpenSRF services which parse the fieldmapper
configuration file and dynamically register OpenSRF methods for creating,
reading, updating, and deleting all of the defined classes.
<class id="mous" controller="open-ils.cstore open-ils.pcrud"
oils_obj:fieldmapper="money::open_user_summary"
oils_persist:tablename="money.open_usr_summary"
reporter:label="Open User Summary"> (1)
<fields oils_persist:primary="usr" oils_persist:sequence=""> (2)
<field name="balance_owed" reporter:datatype="money" /> (3)
<field name="total_owed" reporter:datatype="money" />
<field name="total_paid" reporter:datatype="money" />
<field name="usr" reporter:datatype="link"/>
</fields>
<links>
<link field="usr" reltype="has_a" key="id" map="" class="au"/> (4)
</links>
<permacrud xmlns="http://open-ils.org/spec/opensrf/IDL/permacrud/v1"> (5)
<actions>
<retrieve permission="VIEW_USER"> (6)
<context link="usr" field="home_ou"/> (7)
</retrieve>
</actions>
</permacrud>
</class>| 1 | The <class> element defines the class:
|
| 2 | The <fields> element lists all of the fields that belong to the object.
|
| 3 | Each <field> element defines a single field with the following attributes:
|
| 4 | The <links> element contains a set of zero or more <link> elements,
each of which defines a relationship between the class being described and
another class.
|
| 5 | The <permacrud> element defines the permissions that must have been
granted to a user to operate on instances of this class. |
| 6 | The <retrieve> element is one of four possible children of the
<actions> element that define the permissions required for each action:
create, retrieve, update, and delete.
|
| 7 | The rarely-used <context> element identifies a linked field (link
attribute) in this class which links to an external class that holds the field
(field attribute) that identifies the library within the system for which the
user must have privileges to work. |
When you retrieve an instance of a class, you can ask for the result to flesh some or all of the linked fields of that class, so that the linked instances are returned embedded directly in your requested instance. In that same request you can ask for the fleshed instances to in turn have their linked fields fleshed. By bundling all of this into a single request and result sequence, you can avoid the network overhead of requiring the client to request the base object, then request each linked object in turn.
You can also iterate over a collection of instances and set the automatically
generated isdeleted, isupdated, or isnew properties to indicate that
the given instance has been deleted, updated, or created respectively.
Evergreen can then act in batch mode over the collection to perform the
requested actions on any of the instances that have been flagged for action.
Returning streaming results
In the previous implementation of the opensrf.simple-text.split method, we
returned a reference to the complete array of results. For small values being
delivered over the network, this is perfectly acceptable, but for large sets of
values this can pose a number of problems for the requesting client. Consider a
service that returns a set of bibliographic records in response to a query like
"all records edited in the past month"; if the underlying database is
relatively active, that could result in thousands of records being returned as
a single network request. The client would be forced to block until all of the
results are returned, likely resulting in a significant delay, and depending on
the implementation, correspondingly large amounts of memory might be consumed
as all of the results are read from the network in a single block.
OpenSRF offers a solution to this problem. If the method returns results that
can be divided into separate meaningful units, you can register the OpenSRF
method as a streaming method and enable the client to loop over the results one
unit at a time until the method returns no further results. In addition to
registering the method with the provided name, OpenSRF also registers an additional
method with .atomic appended to the method name. The .atomic variant gathers
all of the results into a single block to return to the client, giving the caller
the ability to choose either streaming or atomic results from a single method
definition.
In the following example, the text splitting method has been reimplemented to support streaming; very few changes are required:
sub text_split {
my $self = shift;
my $conn = shift;
my $text = shift;
my $delimiter = shift || ' ';
my @split_text = split $delimiter, $text;
foreach my $string (@split_text) { (1)
$conn->respond($string);
}
return undef;
}
__PACKAGE__->register_method(
method => 'text_split',
api_name => 'opensrf.simple-text.split',
stream => 1 (2)
);| 1 | Rather than returning a reference to the array, a streaming method loops
over the contents of the array and invokes the respond() method of the
connection object on each element of the array. |
| 2 | Registering the method as a streaming method instructs OpenSRF to also
register an atomic variant (opensrf.simple-text.split.atomic). |
Error! Warning! Info! Debug!
As hard as it may be to believe, it is true: applications sometimes do not
behave in the expected manner, particularly when they are still under
development. The server language bindings for OpenSRF include integrated
support for logging messages at the levels of ERROR, WARNING, INFO, DEBUG, and
the extremely verbose INTERNAL to either a local file or to a syslogger
service. The destination of the log files, and the level of verbosity to be
logged, is set in the opensrf_core.xml configuration file. To add logging to
our Perl example, we just have to add the OpenSRF::Utils::Logger package to our
list of used Perl modules, then invoke the logger at the desired logging level.
You can include many calls to the OpenSRF logger; only those that are higher than your configured logging level will actually hit the log. The following example exercises all of the available logging levels in OpenSRF:
use OpenSRF::Utils::Logger;
my $logger = OpenSRF::Utils::Logger;
# some code in some function
{
$logger->error("Hmm, something bad DEFINITELY happened!");
$logger->warn("Hmm, something bad might have happened.");
$logger->info("Something happened.");
$logger->debug("Something happened; here are some more details.");
$logger->internal("Something happened; here are all the gory details.")
}If you call the mythical OpenSRF method containing the preceding OpenSRF logger statements on a system running at the default logging level of INFO, you will only see the INFO, WARN, and ERR messages, as follows:
[2010-03-17 22:27:30] opensrf.simple-text [ERR :5681:SimpleText.pm:277:] Hmm, something bad DEFINITELY happened! [2010-03-17 22:27:30] opensrf.simple-text [WARN:5681:SimpleText.pm:278:] Hmm, something bad might have happened. [2010-03-17 22:27:30] opensrf.simple-text [INFO:5681:SimpleText.pm:279:] Something happened.
If you then increase the the logging level to INTERNAL (5), the logs will contain much more information, as follows:
[2010-03-17 22:48:11] opensrf.simple-text [ERR :5934:SimpleText.pm:277:] Hmm, something bad DEFINITELY happened! [2010-03-17 22:48:11] opensrf.simple-text [WARN:5934:SimpleText.pm:278:] Hmm, something bad might have happened. [2010-03-17 22:48:11] opensrf.simple-text [INFO:5934:SimpleText.pm:279:] Something happened. [2010-03-17 22:48:11] opensrf.simple-text [DEBG:5934:SimpleText.pm:280:] Something happened; here are some more details. [2010-03-17 22:48:11] opensrf.simple-text [INTL:5934:SimpleText.pm:281:] Something happened; here are all the gory details. [2010-03-17 22:48:11] opensrf.simple-text [ERR :5934:SimpleText.pm:283:] Resolver did not find a cache hit [2010-03-17 22:48:21] opensrf.simple-text [INTL:5934:Cache.pm:125:] Stored opensrf.simple-text.test_cache.masaa => "here" in memcached server [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:Application.pm:579:] Coderef for [OpenSRF::Application::Demo::SimpleText::test_cache] has been run [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:Application.pm:586:] A top level Request object is responding de nada [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:Application.pm:190:] Method duration for [opensrf.simple-text.test_cache]: 10.005 [2010-03-17 22:48:21] opensrf.simple-text [INTL:5934:AppSession.pm:780:] Calling queue_wait(0) [2010-03-17 22:48:21] opensrf.simple-text [INTL:5934:AppSession.pm:769:] Resending...0 [2010-03-17 22:48:21] opensrf.simple-text [INTL:5934:AppSession.pm:450:] In send [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:AppSession.pm:506:] AppSession sending RESULT to opensrf@private.localhost/_dan-karmic-liblap_1268880489.752154_5943 with threadTrace [1] [2010-03-17 22:48:21] opensrf.simple-text [DEBG:5934:AppSession.pm:506:] AppSession sending STATUS to opensrf@private.localhost/_dan-karmic-liblap_1268880489.752154_5943 with threadTrace [1] ...
To see everything that is happening in OpenSRF, try leaving your logging level set to INTERNAL for a few minutes - just ensure that you have a lot of free disk space available if you have a moderately busy system!
Caching results: one secret of scalability
If you have ever used an application that depends on a remote Web service
outside of your control-say, if you need to retrieve results from a
microblogging service-you know the pain of latency and dependability (or the
lack thereof). To improve response time in OpenSRF applications, you can take
advantage of the support offered by the OpenSRF::Utils::Cache module for
communicating with a local instance or cluster of memcache daemons to store
and retrieve persistent values.
use OpenSRF::Utils::Cache; (1)
sub test_cache {
my $self = shift;
my $conn = shift;
my $test_key = shift;
my $cache = OpenSRF::Utils::Cache->new('global'); (2)
my $cache_key = "opensrf.simple-text.test_cache.$test_key"; (3)
my $result = $cache->get_cache($cache_key) || undef; (4)
if ($result) {
$logger->info("Resolver found a cache hit");
return $result;
}
sleep 10; (5)
my $cache_timeout = 300; (6)
$cache->put_cache($cache_key, "here", $cache_timeout); (7)
return "There was no cache hit.";
}This example:
| 1 | Imports the OpenSRF::Utils::Cache module |
| 2 | Creates a cache object |
| 3 | Creates a unique cache key based on the OpenSRF method name and request input value |
| 4 | Checks to see if the cache key already exists; if so, it immediately returns that value |
| 5 | If the cache key does not exist, the code sleeps for 10 seconds to simulate a call to a slow remote Web service, or an intensive process |
| 6 | Sets a value for the lifetime of the cache key in seconds |
| 7 | When the code has retrieved its value, then it can create the cache entry, with the cache key, value to be stored ("here"), and the timeout value in seconds to ensure that we do not return stale data on subsequent calls |
Initializing the service and its children: child labour
When an OpenSRF service is started, it looks for a procedure called
initialize() to set up any global variables shared by all of the children of
the service. The initialize() procedure is typically used to retrieve
configuration settings from the opensrf.xml file.
An OpenSRF service spawns one or more children to actually do the work
requested by callers of the service. For every child process an OpenSRF service
spawns, the child process clones the parent environment and then each child
process runs the child_init() process (if any) defined in the OpenSRF service
to initialize any child-specific settings.
When the OpenSRF service kills a child process, it invokes the child_exit()
procedure (if any) to clean up any resources associated with the child process.
Similarly, when the OpenSRF service is stopped, it calls the DESTROY()
procedure to clean up any remaining resources.
Retrieving configuration settings
The settings for OpenSRF services are maintained in the opensrf.xml XML
configuration file. The structure of the XML document consists of a root
element <opensrf> containing two child elements:
-
<default>contains an<apps>element describing all OpenSRF services running on this system — see Registering a service with the OpenSRF configuration files --, as well as any other arbitrary XML descriptions required for global configuration purposes. For example, Evergreen uses this section for email notification and inter-library patron privacy settings. -
<hosts>contains one element per host that participates in this OpenSRF system. Each host element must include an<activeapps>element that lists all of the services to start on this host when the system starts up. Each host element can optionally override any of the default settings.
OpenSRF includes a service named opensrf.settings to provide distributed
cached access to the configuration settings with a simple API:
-
opensrf.settings.default_config.get: accepts zero arguments and returns the complete set of default settings as a JSON document -
opensrf.settings.host_config.get: accepts one argument (hostname) and returns the complete set of settings, as customized for that hostname, as a JSON document -
opensrf.settings.xpath.get: accepts one argument (an XPath expression) and returns the portion of the configuration file that matches the expression as a JSON document
For example, to determine whether an Evergreen system uses the opt-in
support for sharing patron information between libraries, you could either
invoke the opensrf.settings.default_config.get method and parse the
JSON document to determine the value, or invoke the opensrf.settings.xpath.get
method with the XPath /opensrf/default/share/user/opt_in argument to
retrieve the value directly.
In practice, OpenSRF includes convenience libraries in all of its client
language bindings to simplify access to configuration values. C offers
osrfConfig.c, Perl offers OpenSRF::Utils::SettingsClient, and Python offers
osrf.set. These libraries locally cache the configuration file to avoid
network roundtrips for every request and enable the developer to request
specific values without having to manually construct XPath expressions.
Getting under the covers with OpenSRF
Now that you have seen that it truly is easy to create an OpenSRF service, we can take a look at what is going on under the covers to make all of this work for you.
Get on the messaging bus - safely
One of the core innovations of OpenSRF was to use the Extensible Messaging and Presence Protocol (XMPP, more colloquially known as Jabber) as the messaging bus that ties OpenSRF services together across servers. XMPP is an "XML protocol for near-real-time messaging, presence, and request-response services" (http://www.ietf.org/rfc/rfc3920.txt) that OpenSRF relies on to handle most of the complexity of networked communications. OpenSRF achieves a measure of security for its services through the use of public and private XMPP domains; all OpenSRF services automatically register themselves with the private XMPP domain, but only those services that register themselves with the public XMPP domain can be invoked from public OpenSRF clients.
In a minimal OpenSRF deployment, two XMPP users named "router" connect to the XMPP server, with one connected to the private XMPP domain and one connected to the public XMPP domain. Similarly, two XMPP users named "opensrf" connect to the XMPP server via the private and public XMPP domains. When an OpenSRF service is started, it uses the "opensrf" XMPP user to advertise its availability with the corresponding router on that XMPP domain; the XMPP server automatically assigns a Jabber ID (JID) based on the client hostname to each service’s listener process and each connected drone process waiting to carry out requests. When an OpenSRF router receives a request to invoke a method on a given service, it connects the requester to the next available listener in the list of registered listeners for that service.
The opensrf and router user names, passwords, and domain names, along with the
list of services that should be public, are contained in the opensrf_core.xml
configuration file.
Message body format
OpenSRF was an early adopter of JavaScript Object Notation (JSON). While XMPP is an XML protocol, the Evergreen developers recognized that the compactness of the JSON format offered a significant reduction in bandwidth for the volume of messages that would be generated in an application of that size. In addition, the ability of languages such as JavaScript, Perl, and Python to generate native objects with minimal parsing offered an attractive advantage over invoking an XML parser for every message. Instead, the body of the XMPP message is a simple JSON structure. For a simple request, like the following example that simply reverses a string, it looks like a significant overhead: but we get the advantages of locale support and tracing the request from the requester through the listener and responder (drone).
<message from='router@private.localhost/opensrf.simple-text'
to='opensrf@private.localhost/opensrf.simple-text_listener_at_localhost_6275'
router_from='opensrf@private.localhost/_karmic_126678.3719_6288'
router_to='' router_class='' router_command='' osrf_xid=''
>
<thread>1266781414.366573.12667814146288</thread>
<body>
[
{"__c":"osrfMessage","__p":
{"threadTrace":"1","locale":"en-US","type":"REQUEST","payload":
{"__c":"osrfMethod","__p":
{"method":"opensrf.simple-text.reverse","params":["foobar"]}
}
}
}
]
</body>
</message><message from='opensrf@private.localhost/opensrf.simple-text_drone_at_localhost_6285'
to='opensrf@private.localhost/_karmic_126678.3719_6288'
router_command='' router_class='' osrf_xid=''
>
<thread>1266781414.366573.12667814146288</thread>
<body>
[
{"__c":"osrfMessage","__p":
{"threadTrace":"1","payload":
{"__c":"osrfResult","__p":
{"status":"OK","content":"raboof","statusCode":200}
} ,"type":"RESULT","locale":"en-US"}
},
{"__c":"osrfMessage","__p":
{"threadTrace":"1","payload":
{"__c":"osrfConnectStatus","__p":
{"status":"Request Complete","statusCode":205}
},"type":"STATUS","locale":"en-US"}
}
]
</body>
</message>The content of the <body> element of the OpenSRF request and result should
look familiar; they match the structure of the OpenSRF over
HTTP examples that we previously dissected.
Registering OpenSRF methods in depth
Let’s explore the call to PACKAGE→register_method(); most of the elements
of the hash are optional, and for the sake of brevity we omitted them in the
previous example. As we have seen in the results of the introspection call, a
verbose registration method call is recommended to better enable the internal
documentation. So, for the sake of completeness here, is the set of elements
that you should pass to PACKAGE→register_method():
-
method: the name of the procedure in this module that is being registered as an OpenSRF method -
api_name: the invocable name of the OpenSRF method; by convention, the OpenSRF service name is used as the prefix -
api_level: (optional) can be used for versioning the methods to allow the use of a deprecated API, but in practical use is always 1 -
argc: (optional) the minimal number of arguments that the method expects -
stream: (optional) if this argument is set to any value, then the method supports returning multiple values from a single call to subsequent requests, and OpenSRF automatically creates a corresponding method with ".atomic" appended to its name that returns the complete set of results in a single request; streaming methods are useful if you are returning hundreds of records and want to act on the results as they return -
signature: (optional) a hash describing the method’s purpose, arguments, and return value-
desc: a description of the method’s purpose -
params: an array of hashes, each of which describes one of the method arguments-
name: the name of the argument -
desc: a description of the argument’s purpose -
type: the data type of the argument: for example, string, integer, boolean, number, array, or hash
-
-
return: a hash describing the return value of the method-
desc: a description of the return value -
type: the data type of the return value: for example, string, integer, boolean, number, array, or hash
-
-
Evergreen-specific OpenSRF services
Evergreen is currently the primary showcase for the use of OpenSRF as an application architecture. Evergreen 2.6.0 includes the following set of OpenSRF services:
-
open-ils.acqSupports tasks for managing the acquisitions process -
open-ils.actor: Supports common tasks for working with user accounts and libraries. -
open-ils.auth: Supports authentication of Evergreen users. -
open-ils.auth_proxy: Support using external services such as LDAP directories to authenticate Evergreen users -
open-ils.cat: Supports common cataloging tasks, such as creating, modifying, and merging bibliographic and authority records. -
open-ils.circ: Supports circulation tasks such as checking out items and calculating due dates. -
open-ils.collections: Supports tasks to assist collections services for contacting users with outstanding fines above a certain threshold. -
open-ils.cstore: Supports unrestricted access to Evergreen fieldmapper objects. This is a private service. -
open-ils.fielder -
open-ils.justintime: Support tasks for determining if an action/trigger event is still valid -
open-ils.pcrud: Supports access to Evergreen fieldmapper objects, restricted by staff user permissions. This is a private service. objects. -
open-ils.permacrud: Supports access to Evergreen fieldmapper objects, restricted by staff user permissions. This is a private service. -
open-ils.reporter: Supports the creation and scheduling of reports. -
open-ils.reporter-store: Supports access to Evergreen fieldmapper objects for the reporting service. This is a private service. -
open-ils.resolverSupport tasks for integrating with an OpenURL resolver. -
open-ils.search: Supports searching across bibliographic records, authority records, serial records, Z39.50 sources, and ZIP codes. -
open-ils.serial: Support tasks for serials management -
open-ils.storage: A deprecated method of providing access to Evergreen fieldmapper objects. Implemented in Perl, this service has largely been replaced by the much faster C-basedopen-ils.cstoreservice. -
open-ils.supercat: Supports transforms of MARC records into other formats, such as MODS, as well as providing Atom and RSS feeds and SRU access. -
open-ils.trigger: Supports event-based triggers for actions such as overdue and holds available notification emails. -
open-ils.url_verify: Support tasks for validating URLs -
open-ils.vandelay: Supports the import and export of batches of bibliographic and authority records. -
opensrf.settings: Supports communicating opensrf.xml settings to other services.
Of some interest is that the open-ils.reporter-store and open-ils.cstore
services have identical implementations. Surfacing them as separate services
enables a deployer of Evergreen to ensure that the reporting service does not
interfere with the performance-critical open-ils.cstore service. One can also
direct the reporting service to a read-only database replica to, again, avoid
interference with open-ils.cstore which must write to the master database.
There are only a few significant services that are not built on OpenSRF, such as the SIP and Z39.50 servers. These services implement different protocols and build on existing daemon architectures (Simple2ZOOM for Z39.50), but still rely on the other OpenSRF services to provide access to the Evergreen data. The non-OpenSRF services are reasonably self-contained and can be deployed on different servers to deliver the same sort of deployment flexibility as OpenSRF services, but have the disadvantage of not being integrated into the same configuration and control infrastructure as the OpenSRF services.
Evergreen after one year: reflections on OpenSRF
Project Conifer has been live on Evergreen for just over a year now, and as one of the primary technologists I have had to work closely with the OpenSRF infrastructure during that time. As such, I am in a position to identify some of the strengths and weaknesses of OpenSRF based on our experiences.
Strengths of OpenSRF
As a service infrastructure, OpenSRF has been remarkably reliable. We initially deployed Evergreen on an unreleased version of both OpenSRF and Evergreen due to our requirements for some functionality that had not been delivered in a stable release at that point in time, and despite this risky move we suffered very little unplanned downtime in the opening months. On July 27, 2009 we moved to a newer (but still unreleased) version of the OpenSRF and Evergreen code, and began formally tracking our downtime. Since then, we have achieved more than 99.9% availability - including scheduled downtime for maintenance. This compares quite favourably to the maximum of 75% availability that we were capable of achieving on our previous library system due to the nightly downtime that was required for our backup process. The OpenSRF "maximum request" configuration parameter for each service that kills off drone processes after they have served a given number of requests provides a nice failsafe for processes that might otherwise suffer from a memory leak or hung process. It also helps that when we need to apply an update to a Perl service that is running on multiple servers, we can apply the updated code, then restart the service on one server at a time to avoid any downtime.
As promised by the OpenSRF infrastructure, we have also been able to tune our
cluster of servers to provide better performance. For example, we were able to
change the number of maximum concurrent processes for our database services
when we noticed that we seeing a performance bottleneck with database access.
Making a configuration change go live simply requires you to restart the
opensrf.setting service to pick up the configuration change, then restart the
affected service on each of your servers. We were also able to turn off some of
the less-used OpenSRF services, such as open-ils.collections, on one of our
servers to devote more resources on that server to the more frequently used
services and other performance-critical processes such as Apache.
The support for logging and caching that is built into OpenSRF has been particularly helpful with the development of a custom service for SFX holdings integration into our catalog. Once I understood how OpenSRF works, most of the effort required to build that SFX integration service was spent on figuring out how to properly invoke the SFX API to display human-readable holdings. Adding a new OpenSRF service and registering several new methods for the service was relatively easy. The support for directing log messages to syslog in OpenSRF has also been a boon for both development and debugging when problems arise in a cluster of five servers; we direct all of our log messages to a single server where we can inspect the complete set of messages for the entire cluster in context, rather than trying to piece them together across servers.
Weaknesses
The primary weakness of OpenSRF is the lack of either formal or informal documentation for OpenSRF. There are many frequently asked questions on the Evergreen mailing lists and IRC channel that indicate that some of the people running Evergreen or trying to run Evergreen have not been able to find documentation to help them understand, even at a high level, how the OpenSRF Router and services work with XMPP and the Apache Web server to provide a working Evergreen system. Also, over the past few years several developers have indicated an interest in developing Ruby and PHP bindings for OpenSRF, but the efforts so far have resulted in no working code. Without a formal specification, clearly annotated examples, and unit tests for the major OpenSRF communication use cases that could be ported to the new language as a base set of expectations for a working binding, the hurdles for a developer new to OpenSRF are significant. As a result, Evergreen integration efforts with popular frameworks like Drupal, Blacklight, and VuFind result in the best practical option for a developer with limited time — database-level integration — which has the unfortunate side effect of being much more likely to break after an upgrade.
In conjunction with the lack of documentation that makes it hard to get started with the framework, a disincentive for new developers to contribute to OpenSRF itself is the lack of integrated unit tests. For a developer to contribute a significant, non-obvious patch to OpenSRF, they need to manually run through various (undocumented, again) use cases to try and ensure that the patch introduced no unanticipated side effects. The same problems hold for Evergreen itself, although the Constrictor stress-testing framework offers a way of performing some automated system testing and performance testing.
These weaknesses could be relatively easily overcome with the effort through contributions from people with the right skill sets. This article arguably offers a small set of clear examples at both the networking and application layer of OpenSRF. A technical writer who understands OpenSRF could contribute a formal specification to the project. With a formal specification at their disposal, a quality assurance expert could create an automated test harness and a basic set of unit tests that could be incrementally extended to provide more coverage over time. If one or more continual integration environments are set up to track the various OpenSRF branches of interest, then the OpenSRF community would have immediate feedback on build quality. Once a unit testing framework is in place, more developers might be willing to develop and contribute patches as they could sanity check their own code without an intense effort before exposing it to their peers.
Summary
In this article, I attempted to provide both a high-level and detailed overview of how OpenSRF works, how to build and deploy new OpenSRF services, how to make requests to OpenSRF method from OpenSRF clients or over HTTP, and why you should consider it a possible infrastructure for building your next high-performance system that requires the capability to scale out. In addition, I surveyed the Evergreen services built on OpenSRF and reflected on the strengths and weaknesses of the platform based on the experiences of Project Conifer after a year in production, with some thoughts about areas where the right application of skills could make a significant difference to the Evergreen and OpenSRF projects.
Appendix: Python client
Following is a Python client that makes the same OpenSRF calls as the Perl client:
#!/usr/bin/env python
"""OpenSRF client example in Python"""
import osrf.system
import osrf.ses
def osrf_substring(session, text, sub):
"""substring: Accepts a string and a number as input, returns a string"""
request = session.request('opensrf.simple-text.substring', text, sub)
# Retrieve the response from the method
# The timeout parameter is optional
response = request.recv(timeout=2)
request.cleanup()
# The results are accessible via content()
return response.content()
def osrf_split(session, text, delim):
"""split: Accepts two strings as input, returns an array of strings"""
request = session.request('opensrf.simple-text.split', text, delim)
response = request.recv()
request.cleanup()
return response.content()
def osrf_statistics(session, strings):
"""statistics: Accepts an array of strings as input, returns a hash"""
request = session.request('opensrf.simple-text.statistics', strings)
response = request.recv()
request.cleanup()
return response.content()
if __name__ == "__main__":
file = '/openils/conf/opensrf_core.xml'
# Pull connection settings from <config><opensrf> section of opensrf_core.xml
osrf.system.System.connect(config_file=file, config_context='config.opensrf')
# Set up a connection to the opensrf.settings service
session = osrf.ses.ClientSession('opensrf.simple-text')
result = osrf_substring(session, "foobar", 3)
print(result)
print
result = osrf_split(session, "This is a test", " ")
print("Received %d elements: [" % len(result)),
print(', '.join(result)), ']'
many_strings = (
"First I think I'll have breakfast",
"Then I think that lunch would be nice",
"And then seventy desserts to finish off the day"
)
result = osrf_statistics(session, many_strings)
print("Length: %d" % result["length"])
print("Word count: %d" % result["word_count"])
# Cleanup connection resources
session.cleanup()
Python’s dnspython module refuses to read /etc/resolv.conf, so to
access hostnames that are not served up via DNS, such as the extremely common
case of localhost, you may need to install a package like dnsmasq to act
as a local DNS server for those hostnames.
|